21世纪是科技高速发展的时代,互联网渐渐走入人们的生活。互联网就像一张网。把我们紧紧联系起来,现在的衣食住行都离不开互联网科技,下面分享一篇关于互联网科技的文章给大家。
在我们等待基于Ampere GPU架构的消费类显卡发布时,NVIDIA的旗舰级Ampere芯片A100继续刷新世界纪录。全球最大的基于7nm工艺节点的图形芯片于5月发布,在规格和性能方面有大量支持。现在,Ampere A100张量核心加速器已成为OctaBench上记录的最快的GPU。

NVIDIA Ampere A100 HPC Tensor Core GPU成为Octa Bench记录以来最快的GPU,在关闭RTX的情况下,性能比Turing高43%
OTOY的首席执行官Jules Urbach分享了这一壮举。OTOY是Octa Bench的开发人员,Octa Bench是一个基准工具,使用户可以使用Octane Renderer评估GPU性能。OctaneRenderer本身是一个GPU渲染引擎,支持NVIDIA的RTX光线跟踪硬件加速,以提供清晰的渲染场景。
根据Jules的说法,NVIDIA A100 Tensor Core GPU在OctaBench中的得分为446。他还指出,即使关闭了RTX,该分数也比OctaneRender中的Turing GPU平均快43%。此处比较的Turing结果利用了RTX,不像游戏会导致帧速率大幅下降,在OctaRenderer中启用RTX可以带来更好的性能,因为可以使用可用的光线跟踪硬件更快地渲染和完成场景。
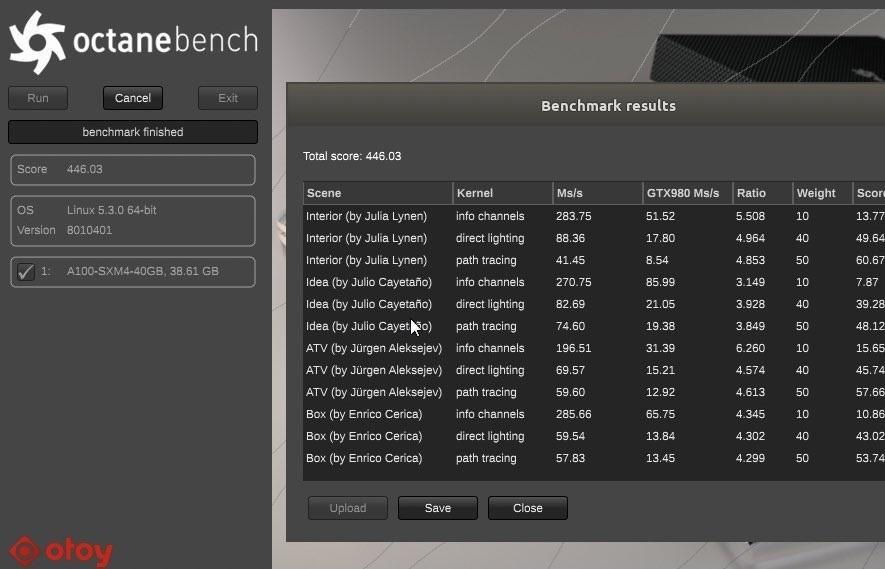
并未说明使用了哪个确切的Turing GPU与NVIDIA Ampere A100 GPU进行比较,但查看所有测试卡的完整平均工作台,我们看到了一系列有趣的结果。平均而言,A100的前身Tesla V100慢20%左右,但出于某种奇怪的原因,Titan V只慢11%,考虑到Titan RTX比A100 GPU慢38%,这令人惊讶。
对此的主要答案可能是,Titan V利用与Tesla V100相同的GV100 GPU,可以针对该数据中心和云规模基准进行更优化,而Turing GPU针对游戏和GP-GPU使用进行更优化。但是,该公司首席执行官再次指出,这是有史以来在特定工作负载上记录的最快的GPU,这对于NVIDIA A100 GPU加速器是一项巨大的壮举。
NVIDIA A100是迄今为止生产的最大的7nm芯片,其特征是在单个晶粒中封装了540亿个巨大的晶体管。由于收益率过高,A100的配置大大降低,但是像Tesla V100一样,一旦收益率提高,我们可能会看到具有更多内核的更高bin版本,这将进一步提高该特定基准测试的性能。

NVIDIA Ampere GA100 GPU的完整实现包括以下单元:
每个完整GPU 8个GPC,8个TPC / GPC,2个SM / TPC,16个SM / GPC,128个SM
每个完整GPU 64个FP32 CUDA内核/ SM,8192个FP32 CUDA内核
每个完整GPU 4个第三代Tensor内核/ SM,512个第三代Tensor内核
6个HBM2堆栈,12个512位内存控制器
NVIDIA Ampere GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
7个GPC,7个或8个TPC / GPC,2个SM / TPC,最多16个SM / GPC,108个SM
每个GPU 64个FP32 CUDA内核/ SM,6912个FP32 CUDA内核
每个GPU 4个第三代Tensor内核/ SM,432个第三代Tensor内核
5个HBM2堆栈,10个512位内存控制器
只能想象启用RTX的Ampere卡投放市场后的性能指标。如果要达到这个特定的基准,那么我们可以看到Ampere GeForce RTX 30系列卡很容易接近其HPC同类产品。